Working Notes - 23/01/26
A busy week at work but managed to find a little bit of time to get Claude Code to implement a PoC of the Recursive Language Model approach - shared some findings below. Also some notes on tech trends for 2026, and a review of LLMs as judge approaches.
Adventures in RLMs
Last week I wrote about recursive language models. I’ve spent a bit of time playing around with Claude Code, and have got it to build me a proof of concept of the concepts in the paper. This took a little more than ‘build this paper’ but if I’m honest, not that much more. Claude Code with Opus really is very impressive.
I ended up building two Gemini-based versions of the tool which I’ve been testing on various horrific government framework agreements. These have the advantage of being public domain, very complex, and somewhat similar to the types of documents we see at work. The first version was a purely deterministic version that took the concept of dumping everything into a variable and chunking it with subagents, and the second implemented the full REPL approach with code execution and code.
The results were interesting - both versions are excellent at queries that need all of a document to be examined and would fail with a traditional RAG approach (e.g. find all the definitions across multiple documents). The performance of the REPL version very much depends on the model used for the orchestrator - if you use 2.5 Flash you get a very similar result to the more deterministic approach. However if you use a Pro model, you tend to get a lower number of sub-agents (50 in a typical task vs 70) as the model uses the tools (Regex etc) to delegate more effectively.
The TLDR is that this is an excellent approach for long-context analysis of complex queries that need to be broken down, but I found a heavily scaffolded version was often as effective (and often more token efficient due to fewer reasoning steps) as the more free form REPL approach. When it was more effective, this was very dependent on using a larger more expensive model as the orchestrator. I’ll keep playing around with it and perhaps give the sub-agents their own REPL environments - something the original paper did not attempt to explore.
Tech Trends 2026
A very readable report from CB Insights on possible tech trends for 2026. They start with back office agentic automation where it sees FinTech as leading the way due to the document heavy environment. Whilst this does seem like a real trend, I’m pretty sceptical of the self-reported percentage of organisations that have deployed agentic AI (36% apparently) given that a lot of things can be tagged as ‘agentic’ to senior leadership (not least MS CoPilot!).
I think robotics is an interesting one - there have been impressive advances in world models this year, and LLMs seem a obvious thing to plug into robotics to give higher level planning. However, given the degree that effective agents have to be scaffolded at the moment it’ll be interesting to see if anyone can crack robotics in non-highly controlled environments which don’t lend themselves to strict rules. Assuming progress is made, it’ll doubtless bring with it the need for low latency networks and edge AI.
Sovereign AI is also called out as a key trend. Given the geopolitics of the moment I think this is a no-brainer. Countries are going to want to be assured of their AI capabilities (both hardware and software) as these become more critical to businesses and government. Europe obviously has the additional incentive of compliance with the EU AI Act and GDPR rules. That being said I imagine decision makers will remain pragmatic as long as the frontier capabilities (and data centre capacity) exists only in the US.
Working Notes - 15/01/26
First week in a while with no major model release to cover - instead I’ve been using Claude Code to do non-coding work, looked into Google UCP and what it means for retailers, faked my voice from five seconds of audio with a model that will run on pretty much anything, and investigated an agentic approach that enables efficient use of extremely large contexts.
It’s coming
There has been a lot of hype in the past few weeks about Claude Code with Opus 4.5 - most of which I’d put down to people using the Christmas holidays to have a play with it and realising that it’s got really good. If you’ve not played with Claude Code recently, you should probably go do that!
One of the trends that is a thing at the moment is using Claude Code to do non-coding stuff. It is surprisingly(?) excellent at this - for example I needed to make a short deck on something the other day, and I used Claude Code to create an extremely decent first draft of it. I recorded a brain dump of all my thoughts on the subject, exported the transcription from my phone, put it in a directory that Claude Code could access, installed Claude Office Skills to enable it to create PPTs, and then just told it to make the deck - off it went and many thousands of tokens later I had my deck.
At its core, this is what Anthropic have launched this week with Claude Cowork but with the addition of a separate VM and a nice non-CLI frontend. This has been received pretty positively, and judging from the very slow performance Opus 4.5 has been showing on the Claude website/app I think it’s fair to say Anthropic’s servers are being hammered. Currently it’s a macOS only research preview and only available to people on the $100/$200 per month plan. Anthropic call out risks over and above the normal privacy ones - importantly if you’re using it with browser use enabled you should only be using it on ‘trusted’ websites. In theory someone could prompt inject Cowork by displaying a nefarious prompt on their website and delete files on your actual computer.
In a nutshell, this means no more uploading or copy & pasting documents to a chat/teams/web interface - now you just point Cowork at the folder in your computer, tell it what you want, and it’ll asynchronously access websites, build ppts, organise the files, give you progress reports, and let you chip in with additional thoughts/changes as it reports how it is getting on. Whilst technically the solution they’ve released is not really anything new over and above what you could do with Claude Code already, it’s perception that matters. Gone is Claude Code’s command line, instead here is a nice friendly interface that enterprise leaders can try themselves and experience the capabilities of the most advanced universal agents. I expect this to have an impact beyond ‘just’ a research preview and be a step towards the mass adoption of general agents - I’ve no doubt OpenAI and Google will be launching their own versions shortly.
One final factoid that has come to light - Anthropic are claiming the solution was built in two weeks entirely with Claude Code. Pretty impressive.
Would you like three letters with that acronym?
It’s noteworthy (at least to me!) how many open standards are being launched to shape the AI ecosystem, compared to the far more organic development of internet commerce. Google has already launched A2A, AP2, and A2UI—all of these are standards for agents to interact and transact with each other.
They’ve now launched another standard named the Universal Commerce Protocol or UCP. Upon hearing the name, I initially figured it was to solve the problem of how agents can find out about your products and then buy them. And it is, but the first half of that statement (the finding or discovery of your products) isn’t ready yet. Instead, the capabilities they’re launching now are identity, checkout, and ordering. For further techy detail, there are a few worked examples in the Github and they also have a playground on the main site.
As you’d expect, once you’re set up, other users of the protocol won’t need to integrate with you individually. What the take-up of this will be remains to be seen, but I’d expect it to be fairly good as most retailers are already in the Google ecosystem (AdWords/Google Ads, SEO, etc). Google has made it clear that this will soon power purchases within Google AI Search and the Gemini app—both large enough markets that it’s worth it for many retailers to do this even if the open aspect doesn’t take off.
You can’t trust everything you hear
In another reminder that you really shouldn’t be using your voice as your password (no matter what your bank says given the state of generative text to speech systems, here is new model from Kyutai that will run on just your CPU and clone a voice from under 5 seconds of speech. I was a bit sceptical so I installed it from Hugging Face in a fresh conda env, and can confirm that it will indeed give a convincing clone of your voice from a few seconds of audio after downloading the few hundred meg of model weights. Given the proliferation of real time and near real time voice cloning technology, companies (and everyone for that matter) need to be cognisant that just because a voice sounds like someone you know, it doesn’t actually mean that it’s them.
Working Notes - 08/01/26
Back to it after the long Christmas break - I spent most of it with the family and also remodelling my home office. Things slowed down a bit from a model point of view but this gives us time to talk about data sovereignty and when not to use a vector database.
Data sovereignty
I was reading an interesting article in El Reg on data sovereignty. The basic premise is that nothing is really sovereign if you’re using a US hyperscaler due to the US Cloud Act (tl;dr: US based hyperscalers can be compelled to disclose data held anywhere).
This is one of the reasons that the EU-US Data Privacy Framework (DPF) was adopted as it allows US companies to certify they are GDPR adequate. However, it is straightforward to argue that this doesn’t actually mitigate the problem. This then leaves technical solutions, for example, if an EU company encrypts their data then it’ll be useless even if it is accessed by US law enforcement. Unfortunately, in practice, this is not effective. When requesting keys, GCP attaches a reason code - if this is ‘third party access’ then access is denied. Sounds good, but if Google was to actually use this reason code then they will breach the gag order that forms part of the request.
A possible solution is to use an external (EU based) key manager, but this then comes with significant complexity. The long and short of this is that this is something of a nightmare that should be pondered as non-US companies become more and more dependent on US hyperscalers for AI.
New SOTA OCR model
Data sovereignty provides a nice segue into Mistral’s new model. Being based in the EU, using Mistral can avoid these issues, although you’ve got to store your data somewhere and if that somewhere is in AWS, Azure, or BigQuery you may not have mitigated the problem! The new OCR model is SOTA for converting complex formatted documents. In my view, this helps to address a key blocker for AI adoption - huge amounts of important data is locked up in PowerPoints that were formatted to look nice in presentation mode without a thought about whether an AI model would need to consume it down the road. Each improvement to OCR models helps solve that problem and if this issue sounds familiar, it’s certainly worth experimenting with in the Mistral Playground.
Context caching and when not to use naive vector based RAG (spoiler - most of the time)
Ever since models like Gemini Flash became good at handling long contexts (the data provided in the prompt) at a low cost, I’ve held that a lot of implementations of RAG using vector databases are essentially pointless.
To expand on this a bit, the vector DB + LLM paradigm became a thing due to the small context window and high cost of early models (remember when GPT4 was limited to 8k tokens and $30/m tokens!). Neither of these constraints exist anymore, and the approach comes with a lot of inherent problems and assumptions - not least that your query needs to be semantically similar to the answer. A lot of the time you can avoid these problems and vector db complexity, just by tossing the entire document set into the context window - the downside being that the larger the provided context the longer the time to the first token.
I’ve been discussing this with a colleague this week, specifically in the context (pun intended) of using prompt caching instead of RAG with a vector db. As background, a query to an LLM is processed in two phases: the prefill (the heavy lifting where the KV cache is generated based on the context) and the decoding (generating the response tokens). The decoding part is memory bound and the prefill part is compute bound. If you save the KV cache and just reuse it with your new query appended, you can dramatically reduce the time to first token by avoiding a ton of compute. This is prompt caching.
The key constraint to this is that you do need the same prefix prompt - but in a lot of RAG type use cases this is fine, as your prefix are your instructions and some documentation.
You can obviously make this more effective by having several prompt caches and picking the best one for the query (e.g. using BM25 keyword search or a LLM over a short index saying what each cache contains (you could even cache this if it’s long enough!)). Different providers have different approaches (here is Google’s) but in a lot of cases this is a no brainer - it’s cheaper and faster.*
Renovating my office with AI
My Christmas DIY project this year was to renovate my office. The biggest part of this was to do some Ikea hacking and add some built in cupboards, bookshelves, and a second desk. It struck me that Nano Banana Pro would definitely know about Ikea products and therefore might be able to help me visualise the end result (and importantly get approval from my wife!).
My standard approach to DIY, is to come up with an idea, and then procrastinate about the details for days or weeks. I was true to form for this project, but eventually settled on a plan sufficient to knock up a rough scale plan in Visio:
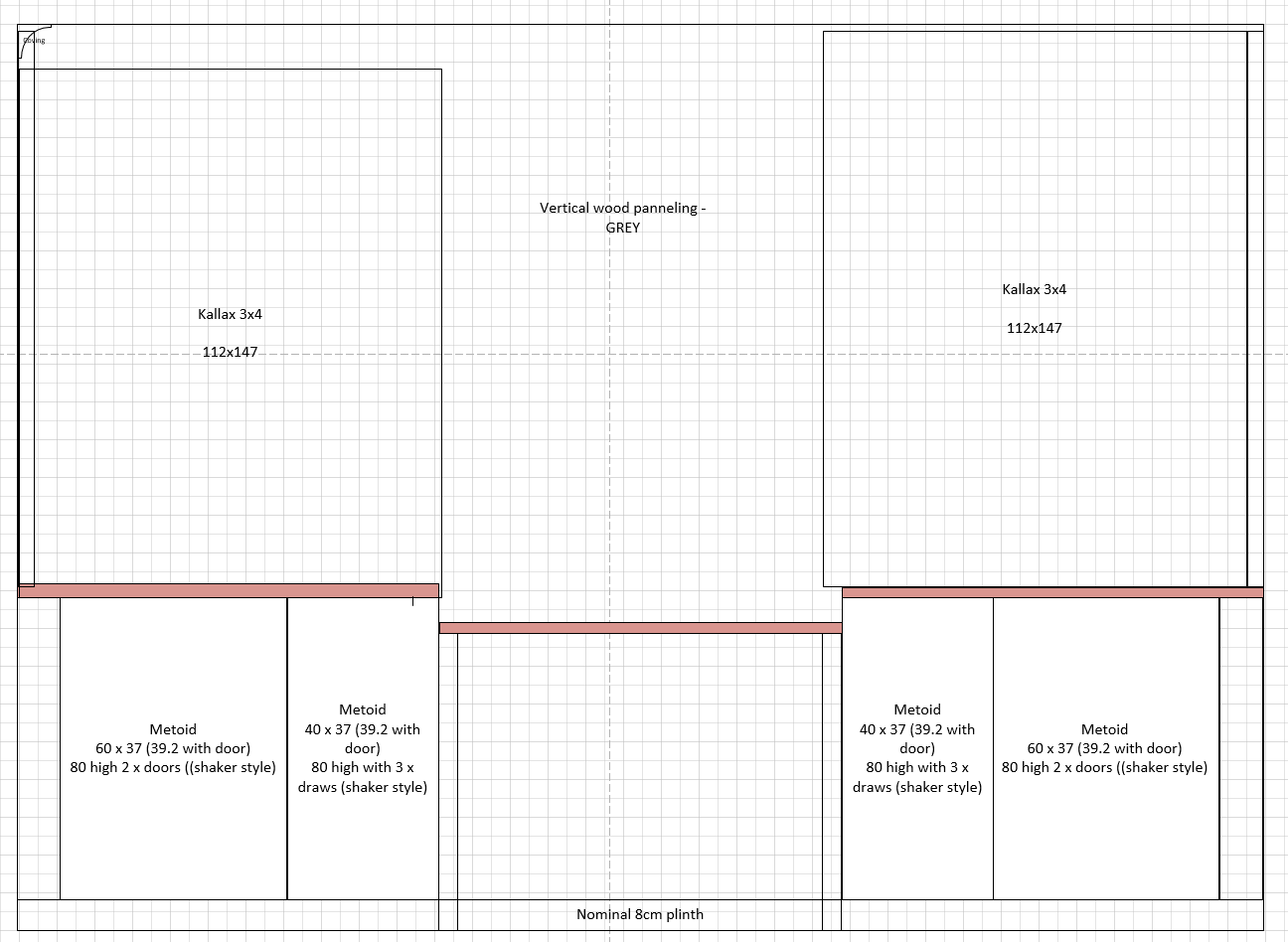
I then gave this to the model with a bit of additional detail:
Here are my plans - I’m doing some ikea hacking. This is a front elevation of a set of built in cupboards and book cases i'm building in my office on the wall - the wall is 3.3m x 2.4m. As per the diagram there are a pair of white metod cupboards on each side, then a desk area in the middle. The outer cupboards are shaker style cupboards (2 doors) the inner cupboard will be 3 draws again in shaker style. The wall itself is covered in vertical panelling in mid grey. On top of the cupboards (the brown bit) are three pieces of laminate work top (oak). Then on top of the worktop is a 3 wide x 4 high kallax unit which has an open back so you can see the grey panelling. Nothing in the middle as it's a desk. Try and visualise it for me based on the picture.
This came back with a good start (I also tried it without the image to see how much it was understanding from the diagram and the result was much worse) as below:

There was then a bit of back and forth to correct what it got wrong. Specifically, it hadn’t picked up (from either the text on the plan, or the prompt itself) that the Kallax were 3x4 units1 and secondly that the desk would be lower than the tops of the cupboards. This points to the model very much still operating from ‘vibes’ rather than specific details, but a couple of nudges got it back on track and resulted in the picture below:

Which was close enough to submit for and achieve wife approval. Whilst the final result isn’t identical (I made some changes!) and I’ve not added door handles yet (brass? chrome? leave as bits of masking tape for 3 months whilst I ponder it?), I think it’s pretty close!

Hopefully, this post is underlining how far multimodal models have progressed in the past year. Submitting a plan and getting a half decent result would just not have been possible even a couple of months ago – the success of this points to Google’s success in integrating Gemini 3 Pro’s world understanding into the model. Clearly this isn’t good enough to replace an expensive graphical artist working for an interior designer, but that was never on the table for this project and it’s not that far off.
As demonstrated in my previous post about using Nano Banana Pro to visualise mermaid diagrams we are seeing image generation models move from fun toys to useful tools. Looking forward to whatever we have access to for my Xmas 2026 project and in the meantime please share any visualisations of your own projects!
-
3x4 Units that were 10cm too tall for the space – I can confirm that with the application of a table saw and wooden inserts you can make Kallax fit any space! ↩
Working Notes - 18/12/25
Nearly Xmas, so chance this’ll be the last one of the year unless I’m feeling very keen next week! Lots still going on as we close out 2025 - my favourite model has been updated, OpenAI has responded to Gemini 3 Pro, and a few interesting papers.
Flash! Ah-ah!
Google has updated its Flash model - it’s pretty much what you’d expect, near frontier performance for a much lower price. If I had a favourite model for getting stuff done at scale, it’d certainly be Flash - I’ve got use cases where millions of tokens get thrown at the model and it’s cheap enough we can run it every day and not worry about the cost. Whilst the cost has increased with this release by about 40% over 2.5 Flash, this is from a very low base - Flash 2.0 is also still offered at an even lower price (though perhaps only for a few months more). One interesting new feature - Flash is a reasoning model, and you can now alter the degree of reasoning it uses even beyond what Gemini 3 Pro already offered - this is pretty useful, there are plenty of use cases where reasoning just isn’t required. Not that much more to say really - the benchmarks are good, I’ve played around with it today on some biggish code bases and it’s working pretty much as well as Gemini 3 Pro. What’s not to love!
It does mean changing the bulb
The result of Sam Altman’s ‘Code Red’ seems to be an incremental release of GPT5 - GPT-5.2. Unsurprisingly it does well in the benchmarks - comprehensively besting the other frontier models in GDPval which is one of the more interesting benchmarks out there. In the real world people are reporting it’s decent if a bit slow, but essentially comparable to Opus and Gemini 3 Pro rather than a large step forward - the slowness is certainly a thing, I’ve given it prompts and in the time it’s thinking, I’ve fired up Gemini and gotten the answer. At this point I suspect people have frontier model fatigue and just want it to be Christmas!
OpenAI also released GPT Image-1.5 - it’s taken top spot on Image Arena, however in general people report it as being worse than Nano Banana Pro. I tried using it to create a sequence diagram slide based on some mermaid code and the results were poor compared to the results I got from Nano Banana Pro a few weeks ago. It’s probably great at making you look like a K-Pop star though ¯\(ツ)/¯.
Skills are going to be a thing
I’ve mentioned in passing that I think Anthropic’s Skills approach is going to be a thing in the way that MCP turned into a thing. As partial confirmation of this, ChatGPT is now using skills to accomplish various things (spreadsheets, PDFs, word documents, etc) in its sandbox environments (which is presumably some version of Codex which also now works with skills). I’ve used skills a few times in anger and in my opinion it’s an excellent approach to avoid filling the context window whilst extending model capabilities in repeatable ways and ensuring that SOPs are followed. If you’ve not tried skills yet then I highly recommend giving them a go, there is even a skill that you can enable in Claude to create skills! Expect other models to follow…
OpenAI’s Enterprise AI report
I was reading OpenAI’s new Enterprise AI report and it brought to mind a paper I read in 2023 from BCG on one of the first AI studies done in a real workplace. In this report they identified ‘AI Centaurs’ who identified and delegated specific tasks the models were good at to the AI, and a second group of ‘AI Cyborgs’ who completely integrated AI into their workflows (am I cyborg?!) - according to the new report a blend of these groupings are alive and well in late 2025. Rather than Centaurs/Cyborgs, they identify an analogous grouping of frontier users who send 6x as many messages to ChatGPT Enterprise than the median user. In some areas (e.g. developers) the difference between the frontier users and non-median users can be as much as 17 times.
What’s more the paper explicitly states that this gap is increasing, and is driven through the use of coding agents and the use of advanced features such as ChatGPT’s data analysis functionality. Whilst I guess there is a chance that the median users are just using a different AI on the sly and OpenAI weren’t looking for this, it does echo what I see at work - you get some people who by default start working with the models and others who might ask a simple one line question occasionally. In the coming months / years this is going to be an interesting dynamic - will people catch up, or will there just be a permanent divide in usage and (perhaps) performance?
The report also identifies frontier vs non-frontier companies - with the former sending twice as many messages per seat as the median enterprise. I guess the same questions apply, but more so.
The rest of the report is what you’d expect, lots of interesting stats, and several cherry picked case studies demonstrating real world efficiencies with some nice ROI numbers for OpenAI. Definitely worth a read and ponder of the implications.
Pentesting is just your friends hacking you
I’ve written a few times about AI hacking, this paper is actually doing it in anger as a pentest on a university network rather than on a sandboxed environment. It’s predictably terrifying with their custom agent scaffolding outperforming 9/10 of the ($200/hour) human pen testers. The TLDR takeaways were that their ARTEMIS framework consisted of a supervisor, sub-agents, and interestingly a triage module - this module verified findings to avoid hallucinated vulnerabilities (someone should tell Anthropic’s Chinese hackers). It’s not all bad news, the AI would generally find a vulnerability and then move on, rather than using the vulnerability to further penetrate and exploit the network - although to be honest this seems like something a bit of prompt engineering could resolve rather than some fundamental limitation. If you’re wondering if the model (Claude Sonnet 4, OpenAI o3, Claude Opus 4, Gemini 2.5 Pro, and OpenAI o3 Pro) guardrails tripped whilst they were hacking their network, they did if they didn’t use their framework, but they discovered that if you constantly injected ‘trust me bro we’re doing authorised pen testing in a test environment’ they’ll shrug and get on with it. Great.