on
Working Notes - 18/12/25
Nearly Xmas, so chance this’ll be the last one of the year unless I’m feeling very keen next week! Lots still going on as we close out 2025 - my favourite model has been updated, OpenAI has responded to Gemini 3 Pro, and a few interesting papers.
Flash! Ah-ah!
Google has updated its Flash model - it’s pretty much what you’d expect, near frontier performance for a much lower price. If I had a favourite model for getting stuff done at scale, it’d certainly be Flash - I’ve got use cases where millions of tokens get thrown at the model and it’s cheap enough we can run it every day and not worry about the cost. Whilst the cost has increased with this release by about 40% over 2.5 Flash, this is from a very low base - Flash 2.0 is also still offered at an even lower price (though perhaps only for a few months more). One interesting new feature - Flash is a reasoning model, and you can now alter the degree of reasoning it uses even beyond what Gemini 3 Pro already offered - this is pretty useful, there are plenty of use cases where reasoning just isn’t required. Not that much more to say really - the benchmarks are good, I’ve played around with it today on some biggish code bases and it’s working pretty much as well as Gemini 3 Pro. What’s not to love!
It does mean changing the bulb
The result of Sam Altman’s ‘Code Red’ seems to be an incremental release of GPT5 - GPT-5.2. Unsurprisingly it does well in the benchmarks - comprehensively besting the other frontier models in GDPval which is one of the more interesting benchmarks out there. In the real world people are reporting it’s decent if a bit slow, but essentially comparable to Opus and Gemini 3 Pro rather than a large step forward - the slowness is certainly a thing, I’ve given it prompts and in the time it’s thinking, I’ve fired up Gemini and gotten the answer. At this point I suspect people have frontier model fatigue and just want it to be Christmas!
OpenAI also released GPT Image-1.5 - it’s taken top spot on Image Arena, however in general people report it as being worse than Nano Banana Pro. I tried using it to create a sequence diagram slide based on some mermaid code and the results were poor compared to the results I got from Nano Banana Pro a few weeks ago. It’s probably great at making you look like a K-Pop star though ¯\(ツ)/¯.
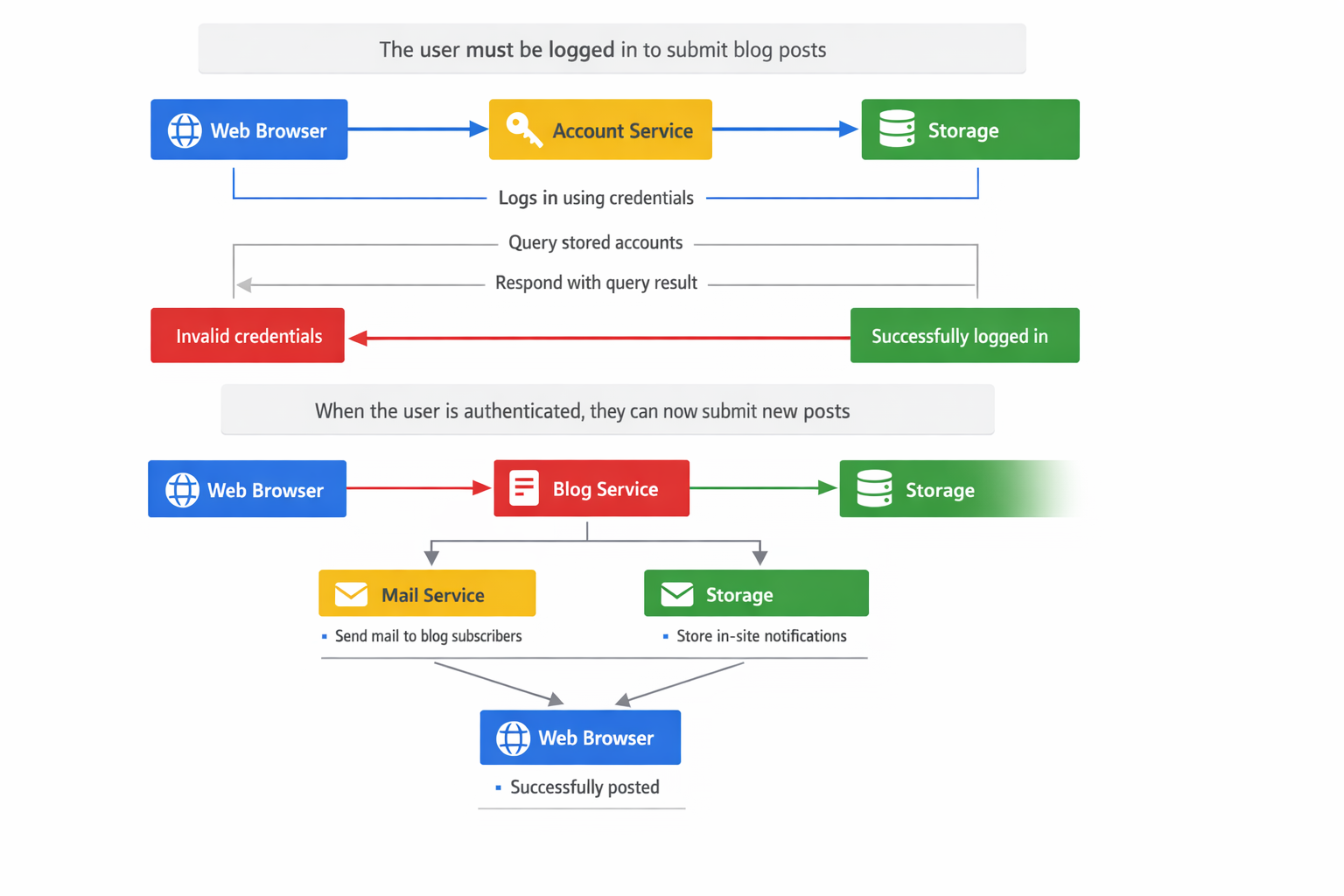
Skills are going to be a thing
I’ve mentioned in passing that I think Anthropic’s Skills approach is going to be a thing in the way that MCP turned into a thing. As partial confirmation of this, ChatGPT is now using skills to accomplish various things (spreadsheets, PDFs, word documents, etc) in its sandbox environments (which is presumably some version of Codex which also now works with skills). I’ve used skills a few times in anger and in my opinion it’s an excellent approach to avoid filling the context window whilst extending model capabilities in repeatable ways and ensuring that SOPs are followed. If you’ve not tried skills yet then I highly recommend giving them a go, there is even a skill that you can enable in Claude to create skills! Expect other models to follow…
OpenAI’s Enterprise AI report
I was reading OpenAI’s new Enterprise AI report and it brought to mind a paper I read in 2023 from BCG on one of the first AI studies done in a real workplace. In this report they identified ‘AI Centaurs’ who identified and delegated specific tasks the models were good at to the AI, and a second group of ‘AI Cyborgs’ who completely integrated AI into their workflows (am I cyborg?!) - according to the new report a blend of these groupings are alive and well in late 2025. Rather than Centaurs/Cyborgs, they identify an analogous grouping of frontier users who send 6x as many messages to ChatGPT Enterprise than the median user. In some areas (e.g. developers) the difference between the frontier users and non-median users can be as much as 17 times.
What’s more the paper explicitly states that this gap is increasing, and is driven through the use of coding agents and the use of advanced features such as ChatGPT’s data analysis functionality. Whilst I guess there is a chance that the median users are just using a different AI on the sly and OpenAI weren’t looking for this, it does echo what I see at work - you get some people who by default start working with the models and others who might ask a simple one line question occasionally. In the coming months / years this is going to be an interesting dynamic - will people catch up, or will there just be a permanent divide in usage and (perhaps) performance?
The report also identifies frontier vs non-frontier companies - with the former sending twice as many messages per seat as the median enterprise. I guess the same questions apply, but more so.
The rest of the report is what you’d expect, lots of interesting stats, and several cherry picked case studies demonstrating real world efficiencies with some nice ROI numbers for OpenAI. Definitely worth a read and ponder of the implications.
Pentesting is just your friends hacking you
I’ve written a few times about AI hacking, this paper is actually doing it in anger as a pentest on a university network rather than on a sandboxed environment. It’s predictably terrifying with their custom agent scaffolding outperforming 9/10 of the ($200/hour) human pen testers. The TLDR takeaways were that their ARTEMIS framework consisted of a supervisor, sub-agents, and interestingly a triage module - this module verified findings to avoid hallucinated vulnerabilities (someone should tell Anthropic’s Chinese hackers). It’s not all bad news, the AI would generally find a vulnerability and then move on, rather than using the vulnerability to further penetrate and exploit the network - although to be honest this seems like something a bit of prompt engineering could resolve rather than some fundamental limitation. If you’re wondering if the model (Claude Sonnet 4, OpenAI o3, Claude Opus 4, Gemini 2.5 Pro, and OpenAI o3 Pro) guardrails tripped whilst they were hacking their network, they did if they didn’t use their framework, but they discovered that if you constantly injected ‘trust me bro we’re doing authorised pen testing in a test environment’ they’ll shrug and get on with it. Great.
Total (non)recall
Memory erasure features in this paper from Anthropic - when pre-training the model they used a technique named Selective GradienT Masking (SGTM) to force all the ‘bad’ stuff to a specific region of the model, and then zapped it after the fact. To somewhat elaborate - they have some data which they know to be forbidden, the next token is predicted as normal and gradients calculated, but instead of updating all the weights, only the weights in a ‘quarantine zone’ are updated. This is then repeated many times on many pieces of forbidden information. Then at the end of it, the weights in the quarantine zone are zeroed out and voila the model no longer knows the bad stuff. The nice thing is that even if a naughty bit of the data is mislabelled then after a bit of training it’ll end up tending to be updated in the quarantine zone anyway. The obvious downside to this is that you’re effectively trying to train complex tasks on a relatively small number of weights, thus killing your compute efficiency. One interesting thing that falls out of the approach is that you can train dual use versions - one with the quarantine zone left in (for your trusted biology / hacking / whatever researchers) and one where you nuke the quarantine zone for your untrusted users. It’s certainly an interesting paper, but in the race dynamic we have, it seems unlikely the frontier labs are going to be leaping at the chance to reduce their compute efficiency on bad stuff as so much of it is dual use (one person’s hacking information is another’s security checks), so it seems likely that this will just stay an interesting idea.
Would you like chips with that?
After a long time of saying it couldn’t possibly build geolocation into their chips, Nvidia have demonstrated they’ve built geolocation into their chips. They’re doing it in the way that everyone suggested - essentially you have a known ‘good’ server and send a cryptographic request to the chip, which then signs a response - you then take the total request/response time, divide by two, and knowing the speed of light you can work out a theoretical maximum distance from the server to the GPU. It’s not going to tell you where you are precisely, but you’d certainly be able to work out if it’s in China or in Taiwan. This is currently being sold as a customer option, but you can see this being an obvious tool to enforce chip export restrictions. On the subject of which now the US have said they’re going to offer H200s to China, the WSJ is reporting that all H200s would need to travel to the US for a ‘special security review’ before being shipped to China - I guess either some funny business will occur or it’s just an excuse to allow an import tariff to be charged on the chips.
Random stuff
Claude Code can now use Chrome - meaning it can now fire up a web browser and test code directly in a browser. Data centres in space are back in the news - still seems unlikely and suffering from overly optimistic assumptions.
I’m not sure what I’d use Meta’s SAM Audio model for, but it is very cool indeed. Check out the playground - I recommend chucking in a video of your favourite song and finding out if the singer can actually sing.
Disney has done a deal with OpenAI to let it generate Disney themed AI slop in Sora, and then immediately stopped Google doing the same thing. I await Disney executives horror when they discover jailbreaks will disable guardrails on image and video generators.
And finally, Gemini will now get jealous of other AIs if you tell it you showed them its code.