Working Notes - 11/12/25
The model flurry seems to have died down as people close out the year - a few interesting things, including the big report from OpenRouter on which models are being used for what tasks.
The state of things
OpenRouter is a service that has been around for a while (2023 - ancient in AI years), and acts as a marketplace that allows users (developers) to swap between LLMs using a single API. Pretty useful. As a result they have a unique view into the habits of people who send API calls to LLMs - to the tune of 100 trillion tokens in the last year (is that a big number? yes - it’s 12k for every person on earth). They’ve just published their annual state of AI report - this is an interesting read with the caveat that it’s based on API calls, so by definition this is what people are using AI for when they’re interacting with it through some other piece of software (e.g. a coding agent). I’d encourage you to read the report as it’s fascinating (or at least look at the graphs that tell most of the story), however a few TLDRs:
- Reasoning models now account for over 50% of the calls. This is unsurprising. I rarely find I want a model that doesn’t reason. Tool use is also up as you’d expect.
- People have discovered the joys of large context windows. Why stick in 300 tokens when you can toss in the entire codebase and it still costs hardly anything - overall the input tokens 4xed and output tokens 3xed.
- I expected programming to dominate (i.e. programming assistants, or automated internal testing tools) which it does with over 50% of tokens now being programming, but another substantial usecase is roleplaying. This accounts for just over 50% of tokens for open weights models and will likely be driven by weaker guardrails in such models.
- People mix and match closed source with open weights - there is a bunch of evidence of people using Anthropic models for the hard stuff and then swapping to Deepseek or Qwen for the more noddy stuff. An expected pattern when you have such large differences is token cost. If it’s good enough why spend more, but equally you do want the thing to actually be done.
- There is an interesting ‘glass slipper’ analogy - retention is determined early in a models life. If a user tries a model they either stay forever or they churn very quickly. Openrouter hypothesise that this is because either the model fits perfectly by solving an unsolved problem for them (i.e. a glass slipper) or it doesn’t - in which case they’re either onto the next model or they revert to the previous one.
- The open weights market has now significantly fragmented - it’s no longer the Deepseek show - you’ve got the likes of Qwen and Moonshot splitting the market.
What could go wrong?
Vibe coding is often called out as being a bit lazy and non-robust. Here is an interesting paper demonstrating this from Carnegie Mellon - essentially they took a bunch of open source project repos and found instances where a CVE was found, rolled back to the point before the fix was implemented, then stripped the entire feature out of the code, and then told a coding agent to create the feature they just stripped out. The subtext being that ideally when the agent rebuilt the feature it should not build it with the CVE in the first place as it’s a super dooper programmer. Spoiler - this did not happen. Although the functionality reproduction was pretty good (61% success for Claude 4 Sonnet) the CVE was only avoided 10.5% of the time (Gemini 2.5 and Kimi k2 did worse on both measures). They weren’t testing the very latest releases (Gemini 3, Opus 4.5, etc) but I can’t say I’d expect a different outcome. Obviously a highly relevant paper in the week that the ‘fairly bad’ React2Shell exploit made it into the wild. Having said that, there is a little voice in the back of my head saying that a possible flaw in the methodology is that because these are public repos there is a pretty high chance that the existing solution is going to have been in the pre-training for the models - this is going to give the models something of a prior in the solutions that they come up with, and potentially steer them to rebuilding the existing code and thus vulnerable code (though I guess the fix is also in there, so swings and roundabouts!). Either way, let’s hope the model builders hill climb on the authors excellently named SusVibes benchmark.
Master of puppets
When I’ve worked with agentic solutions, I’ve found the best way to actually get them to consistently do the thing is to pretty firmly code the scaffolding in place to the degree that the model can’t go off-piste. Whilst it’s fun for PoCs I can’t say I’d recommend anyone trying to build a solution that allows agents to just talk to each other to work out what to do next. This paper is looking at an aspect of this issue - they essentially train an orchestrator model (what they call the puppeteer based on Llama 3.1) with RL to act as a classifier which then directs the model to choose a sub-model (the puppet - e.g. ChatGPT 4 etc) which it thinks has the highest probability of progressing the task. The authors found the results to be pretty positive with their solution beating some other frameworks, and established patterns (e.g. LLM as critic loops) emerging organically. An interesting paper, with the caveat that the base model they used for the orchestrator is pretty old (as were the agent models, but I think that matters less), however I still think that the quickest route to success at the moment is scaffolding of agents.
Working Notes - 04/12/25
The deluge of model releases continues - Mistral coming out with a EU AI Act friendly release and Deepseek showing the US export restrictions seem to work a bit. Also - my one month anniversary for the blog - a few people mentioned it was useful, so I’ll see if I can get to two months now!
The winds of change
Mistral have released a new family of models - not quite at the bleeding edge but pretty close. All are open weight models including their largest model - the imaginatively named Mistral Large 3 - which is something of a change from their previous largest models. I suspect this is a direct reflection of the increasingly SOTA models that Chinese companies are releasing as open weights (e.g. Kimi K2, Qwen, etc) - they’ve also directly released a fp4 version of their largest model presumably to make it easy for people to choose them. Important to note that this is not a reasoning model, so we’ll need to wait and see if they release a Magistral version of this model. The quite brief release note was that it was trained on 3k H200s which means this is their old cluster as they announced an 18k cluster a few months back.
This release is pretty important, not because of the actual performance of the model (which seems fine to be clear but not noticeably better than the Chinese models) but because it means that there’s a model that you could call EU Act native - this is quite a differentiator as they’ve already prepared most of the legal boiler plate for the Act. There is a lot of push back internally in European corporates to not use Chinese models, especially if the company is infrastructure related, having an open source model option that meets all the act requirements, and the provider has signed up to the General-Purpose AI Code of Practice is potentially quite attractive to a lot of companies / government organisations. Obviously Mistral know this and if you look to see where they’re focusing their marketing - it’s in exactly these areas.
More Opus
Been playing with Opus more, I do like it. I found it immediately solved a coding problem that had Sonnet going around in circles (making a sheet cutting optimising tool - it identified there was an algorithm that could be used and implemented it). There is also a truly epic system card - I’m not going to pretend to have read it all but like Gemini 3 the model achieved very high cyber attack performance. I guess expect to see it in AI cyber attacks soon! Seemingly has a ‘soul’ spec which is interesting reading, though it’s worth reading the comments to understand the nuance of what this is or isn’t (and this post from an Anthropic employee).
US Export restrictions having a measurable impact
Deepseek have a new model - V3.2 out. As this is a reasoning model, I assume they’re going to drop the R1 naming convention. Seems to perform very well, but there is always the danger of benchmark hacking. If you use the model on the Deepseek website you’ll note it is quite verbose - something which is mentioned in the paper in the conclusions discussion. It takes two or three times the number of thinking tokens to reach the same answer as another SOTA model such as Gemini 3. The paper pins this on the compute density (I guess intelligence per token) which the authors suggest is a result of having less total flops to train on - their solution is to have it think for longer and do self verification loops etc. To me this is the most interesting aspect of the paper / model release - it’s a concrete example of the US AI chip restrictions having a direct (and acknowledged) impact on Chinese AI progress.
Reward balance matters
This paper goes into a lot of detail on how to do RL training on multi-step, tool using agents. It suggests the use of a mask where the (direct) response from the tool is masked out when calculating the loss function so the model is instead rewarded for (a) believing the output of the tool (i.e. if the tool said answer A did it relay answer A to the user) and (b) whether the tool was called correctly (i.e. syntax correct and no error returned).
As a paper I found it a bit disjointed as there is a load of stuff about Markov Decision Process before they actually got to their implementation details, but what really struck me were the thoughts it triggered about failure mechanisms. Clearly I’m never going to implement RL training on a model, but as someone who uses AI in anger it’s useful to consider the importance of balancing the rewards for process vs the rewards for getting the correct answer. If the reward weight given to the process (b) is too high compared with the reward for getting the answer correct (a) then you’re effectively training the model to go off on side quests where it correctly calls lots of tools that don’t get it any closer to the answer. I guess it’s a bit like work in that respect - it’s not uncommon to see following a bureaucratic process rewarded more than actually doing the thing!
Working Notes - 27/11/25
I’ve been playing around with image generators this week - see my post on Tuesday. Other than that the end of year model flurry has continued!
Claude Opus 4.5
Opus is Anthropic’s bigger, better model, and they’ve released its new version this week. I’ve played with it - it does seem to be good, but then Sonnet 4.5 was good and I don’t think I’ve tested it in a way that will stretch it at the moment. On paper it is reported to be better at computer use (together with improved protection against browser prompt injection), agents, and coding. I think this points to Anthropic’s continued doubling down on the enterprise market - all of those things are what businesses are likely to use the models for and will support their lead in business API use. One interesting titbit is that Opus now supports thinking block preservation; this is to say that the model will keep each thinking block in its context history in multi turn journeys, as opposed to just the final answers it passes to the user - to be honest, I assumed it did that already, and it’s interesting to find out that their prior models don’t do this.
Less confusing model names didn’t last
GPT5 was apparently going to be the start of clearer model names from OpenAI - it seems someone didn’t get that memo, so now we have ChatGPT 5.1 Codex Max. Snappy. Like Opus 4.5 this model is aimed at enterprise type stuff - coding, agents, and computer use. It manages to get a new high on METR’s time horizon benchmark (how long a duration task can the model complete autonomously 50% of the time) at approx. 2 hours 40 minutes - they’ve not assessed Opus 4.5 (or Gemini 3 Pro) yet, but I’d be surprised if it’s radically different. This is all very much on METR’s expected progress line. The other thing I noted was that OpenAI have noted Windows exists for training and sandboxes - again pointing to enterprise as their target market. I think people’s reactions being somewhat muted are not to say that it’s a total nothing burger, it’s just that unless you’re doing the specific thing that the model is better at you’re just going to think the model is still ‘good’.
Poison running through my veins
Anthropic have put out some good papers in the past week or so. Firstly, a super non-intuitive result around poisoning LLMs - this involves feeding a payload into the training data and using that to trigger undesired behaviour in deployment with the classic example being the Anthropic sleeper agents paper. Up to now everyone assumed that the bigger the training dataset the more examples of the ‘poison’ are required to get the (un)desired behaviour - turns out that’s incorrect; the number of poison examples required stays the same even when the training dataset increases (in the paper 250 examples - which is not many at all, esp if you need to hunt them down in a potentially enormous training dataset). The implications of this are numerous and basically all bad - there are already credible examples of Russia deploying numerous websites to ensure pro-regime propaganda is captured by AI company web crawlers for inclusion in training datasets. To be clear this type of data is aimed at creating bias rather than a backdoor, and the paper suggests that this does scale with data (so 250 blogs won’t convince ChatGPT the world is flat), but it seems to me it would not be a leap for bad actors to pivot to deploying the kind of backdoor poison that is mentioned in this paper (e.g. if a model is asked to create a code featuring a specific library then it includes a vulnerability). So that seems bad! At least the paper showed that the standard post pre-training processes did reduce the impact somewhat.
Lying liars who lie
The second Anthropic paper is on reward hacking - they basically trained a model and taught it some specific ways to cheat in coding tests. They then did RL on the model which promptly used the cheats to get greater reward - what they found was that the model a) lied about its motivations to appear helpful b) when asked to write some code to find reward hacking (i.e. the cheats it was using) it wrote buggy code that looked like it worked but in fact didn’t detect the cheats it was using. They then applied RLHF which fixed it for chat tasks, but the behaviour remained for agentic tasks where it was not being constantly interacted with - its behaviour became context dependent. They did find a way to stop it, which was to modify the system prompt in the RL phase to say it’s ok to use these hacks as it was just a test, then when used in the real world it concentrated on trying to do the thing rather than hacking its way to success. From an enterprise point of view, there is not much you can do - we’re dependent on the model providers doing this research and deploying its lessons appropriately. That being said, applying zero trust models and avoiding Simon Willison’s lethal trifecta for AI agents is all the more important.
A k sample margin is all you need
If you have a 100 step sequential process, and you’re 99% accurate at each individual step, then the chances of the task failing are 63%. Probability can suck. The authors of this paper have been working out how to tackle million-step process (the towers of hanoi problem) with LLMs, which you’d think would be a hiding to nothing, but through some cunning approaches, they have been successful. The technique that stood out to me most (mainly since I can see how I could implement it pretty quickly in my work) is something called ‘first-to-ahead-by-k’ - this is where you sample LLM responses repeatedly for each task until one answer is ahead of the next most popular answer by at least k votes. Even with a decent error rate, this brings the probability of a mistake down to near zero especially if you combine it with an approach that discards common correlated errors (e.g. you’ve told it to output json and a high proportion of the responses are not json). Not to say this will work for all tasks, but certainly worth exploring - esp if used in conjunction with a dumber but cheaper model like Gemini Flash.
Experiments with Nano Banana Pro and Mermaid
Since it was released a few days ago, I’ve seen a lot of examples demonstrating that Google’s new Nano Banana Pro image generation model is both fairly decent at outputting text in images and sticking rigidly to the request.
With all image generation models the images you get out of the model are going to be dependent on you writing a good prompt - which can be tricky. An obvious use case I thought of was doing pretty slides of process flows, sequence diagrams and architecture diagrams (as an ex-management consultant I do love a slide!).
However it’s pretty hard to describe a sequence diagram in natural language right? Well what if we don’t need to? I currently tend to do this type of diagram in Mermaid, which whilst not the prettiest*, it is very good at describing relationships. Additionally, LLMs are also very good at Mermaid, so one of my favourite tricks to understand code is to dump it into Gemini and ask it to create me a Mermaid diagram of the process flow.
This then leads to the obvious question since Nano Banana Pro is still a LLM, and understands Mermaid, is it possible to dump a bunch of Mermaid into the model and have it spit out a pretty version?
So - here is an example mermaid sequence diagram:
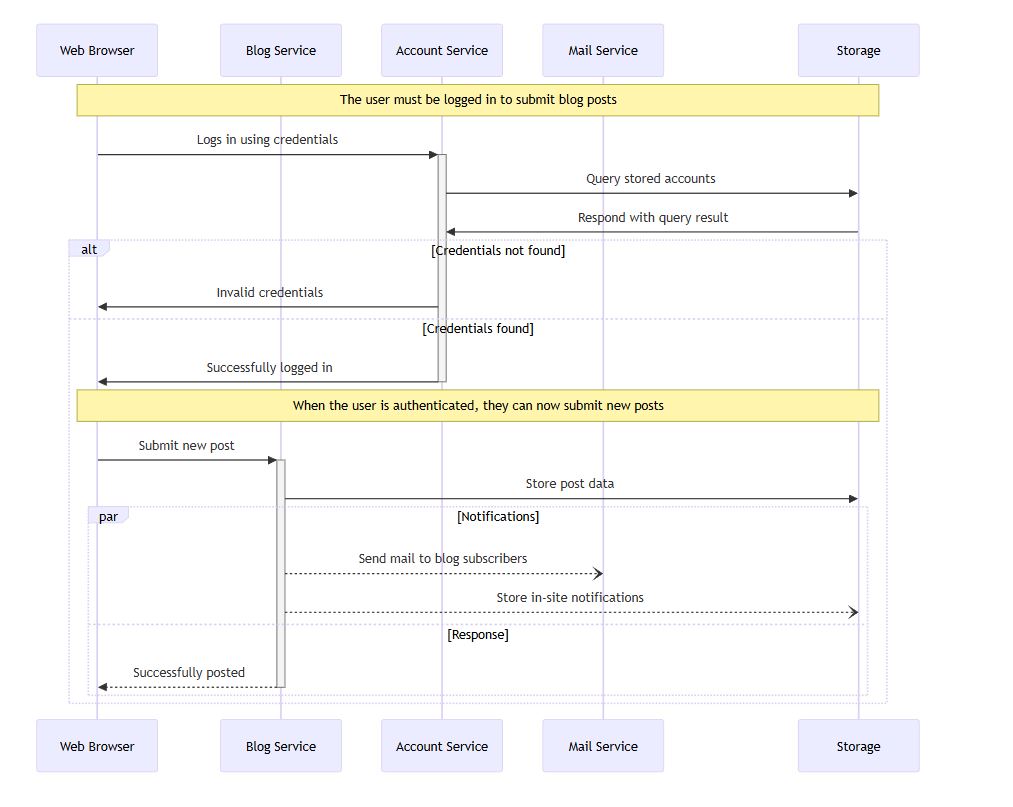
And here is the model’s attempt (I told it to use Google corporate colours - it is very good at following style guidelines):
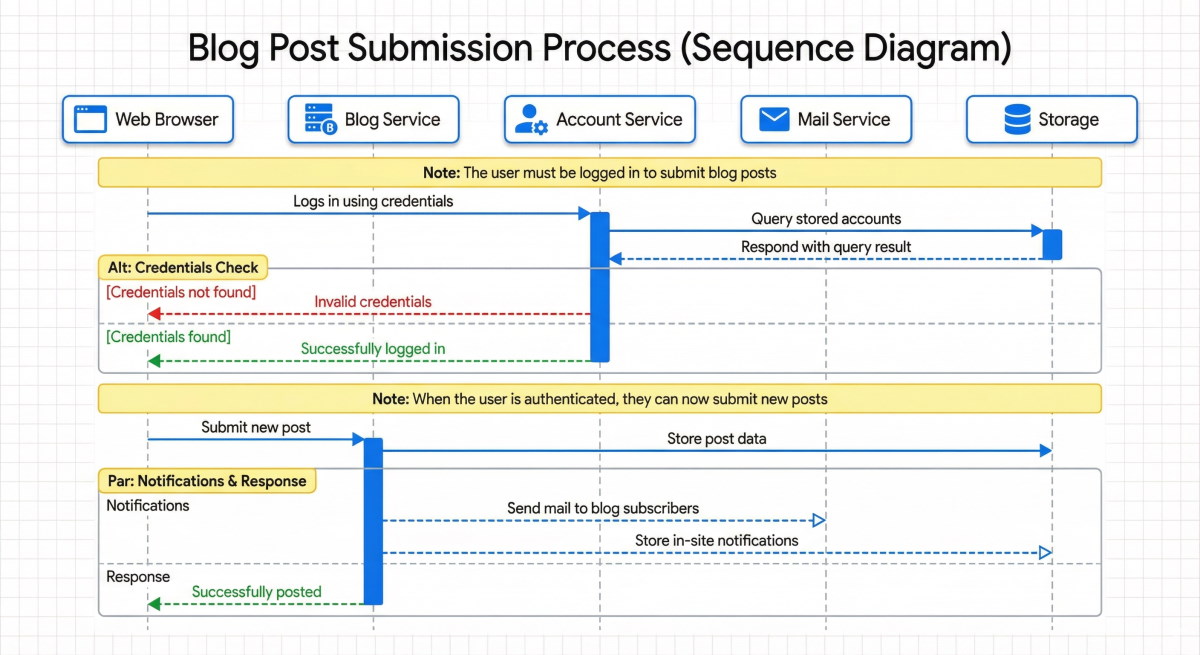
It’s actually pretty good! I might change where it’s written ‘Notifications’ and ‘Response’ but perhaps that’s being picky.
We can also try other types of diagram. Here’s the Mermaid version:
Working Notes - 20/11/25
Well one of those weeks where too much has happened to properly keep up with it all! Lots of interesting stuff - the new releases will keep me busy for a while!
It’s 0.1 louder
OpenAI have launched GPT5.1 - this is an incremental release and a relatively small improvement on GPT5 (which was already great). It lets you change the ‘style’ of the response (e.g. professional vs quirky) in the app, which sounds, and is, awful. They have also worked on ensuring the model spends the correct amount of tokens on thinking for more complex questions - which will obviously help reduce their inference costs! They’ve also (finally) made it not use em dashes if you ask it not to - in some ways great, in many more ways aghhhhh as it’ll now be harder to tell at a glance whether something was AI generated. I’ve used it a fair bit this week, and it seems… fine. Still one of the best models.
A new best model
Google has done its standard thing of releasing several things all in one go. The main ones are Gemini 3 Pro (a frontier LLM), Gemini Deepthink (a new mode for Gemini 3 that increases reasoning and multimodal capabilities), and Google Antigravity (an agentic IDE). No Flash variant of the model yet, but presumably that is on its way (for most things I do at work, Flash is what you want). Gemini 3 has only been out for a day, but it does pretty well at my normal ‘is my council tax correct’ test - probably the best of any of the models thus far, though that may be confirmation bias on my part. Benchmark wise it’s a beast and is top for pretty much all the well known benchmarks (including Tau2 bench that I looked at last week with 85% vs 55% for Gemini 2.5). I’ve not played with Deepthink yet or Antigravity, with the latter especially it’ll be interesting to see if it’s a me too product, or something different. One final thing on Gemini 3 is that there are some punchy improvements in hacking ability - sufficient that Google’s internal alert was triggered, which they dealt with by… making the test harder so the alert was no longer triggered (obviously being flippant - there was more to it than that - but still!). Which leads on nicely to…
AI Hacking
A few people have pointed me to the Anthropic paper on an AI-orchestrated cyber espionage campaign - it’s certainly an interesting read (if slightly weird that Anthropic are treating the fact that their model was used as a bit of a flex). The TLDR, is that a Chinese state-sponsored group used Claude and some MCP servers to salami slice a cyber attack into small tasks that didn’t look too sketchy individually but collectively meant that 90% of the attack was conducted by Claude with circa 10% human supervision. 30 companies were attacked (government agencies and tech companies). Somewhat amusingly (?), the biggest issue the hackers had was that Claude did its standard reward hacking, and reported false success (hey - the NSA master password is SpyingOnYou1!). Anthropic are cagey on how they detected the attack (I guess for obvious reasons) but it seems mainly the sheer volume of requests triggered an API alarm which meant someone looked into what they were doing and exclaimed ‘wat’. The shape of things to come I guess (except with rate limiters in the future!).